
MiniMax M2.7: โมเดลที่พัฒนาตัวเองได้ พร้อม Agent Teams แบบ Native
MiniMax M2.7 มาพร้อม Agent Teams, Self-Evolution และ benchmark ระดับ frontier — รีวิวเชิงลึกสำหรับนักพัฒนา
ถ้า AI พัฒนาตัวเองได้ จะเกิดอะไรขึ้น?
คำถามนี้ฟังดูเหมือนหัวข้อในหนัง sci-fi แต่ MiniMax ตอบคำถามนี้ตรงๆ เมื่อ 18 มีนาคม 2026 ด้วยการปล่อย M2.7 — โมเดลที่พวกเขาบอกชัดเจนว่า "deeply participates in its own evolution" ผ่าน recursive harness iteration กว่า 100 รอบ จนผลลัพธ์ดีขึ้น 30% บน internal evaluations
ฟังดูน่าตื่นเต้น แต่ต้องถอยมาหนึ่งก้าวก่อน "พัฒนาตัวเอง" ในที่นี้ไม่ได้หมายความว่าโมเดลเปิด terminal แล้วเขียน code ปรับ weights ตัวเอง มันหมายความว่า M2.7 ถูกใช้เป็นส่วนหนึ่งของ evaluation pipeline — โมเดลช่วยปรับปรุง harness (ชุดคำสั่งที่กำกับการทำงานของตัวเอง) แล้ววน loop กลับมาวัดผลซ้ำจนได้ผลลัพธ์ที่ดีขึ้น เรียกว่า Research Agent Harness ซึ่งเป็น autonomous evaluation framework ที่ MiniMax พัฒนาขึ้นมาเอง
แต่สิ่งที่น่าสนใจยิ่งกว่าเรื่อง self-evolution คือ Agent Teams — ความสามารถใหม่ที่ให้คุณสร้างทีม AI หลายตัวทำงานร่วมกันแบบ native ไม่ใช่แค่ prompt engineering trick แต่เป็น paradigm ที่ built-in มากับ architecture ของโมเดลตั้งแต่แรก รองรับ dynamic tool search, cross-agent collaboration, และ automatic task decomposition
บทความนี้จะแกะ M2.7 ออกเป็นชิ้นๆ — ตั้งแต่ architecture ของ Research Agent Harness, ตัวเลข benchmark ที่ MiniMax อ้าง, วิธีใช้ API, ไปจนถึงข้อควรระวังที่ต้องรู้ก่อนตัดสินใจเอาไปใช้จริง
56.2%
SWE-Pro (เทียบ GPT-5.3 Codex)
97%
Skill Adherence Rate
40+
Complex Skills รองรับ

ที่มา: MiniMax Official Announcement — ภาพรวม benchmark ของ M2.7 เทียบกับ frontier models
Agent Teams คืออะไร — และทำไมมันถึงสำคัญกว่าตัวเลข benchmark?
หลายคนอ่านข่าว M2.7 แล้วโฟกัสที่ตัวเลข SWE-Pro 56.2% หรือ MLE Bench Lite 66.6% แต่ถ้าถามว่าอะไรคือ ของจริง ที่เปลี่ยน workflow ได้ — คำตอบคือ Agent Teams ไม่ใช่ตัวเลขบน leaderboard
แนวคิดหลักคือแทนที่จะมี AI ตัวเดียวทำทุกอย่าง คุณสร้าง "ทีม" ของ agents ที่แต่ละตัวมี specialization ต่างกัน ตัวหนึ่งเชี่ยวชาญ code review ตัวหนึ่งถนัด database optimization อีกตัวเก่งเรื่อง documentation — แล้วปล่อยให้มันแบ่งงานกันเอง ผ่าน automatic task decomposition ที่ built-in มากับโมเดล ไม่ต้องเขียน orchestration logic เอง
สิ่งที่ทำให้ Agent Teams ต่างจากการใช้ multi-agent framework ข้างนอก (เช่น LangGraph หรือ AutoGen) คือมันทำงานที่ระดับ inference layer ของโมเดลเลย — agents แชร์ context ได้โดยไม่ต้อง serialize/deserialize ข้อมูลข้ามระบบ รองรับ dynamic tool search ที่ agent สามารถค้นหาและเรียกใช้ tools ใหม่ได้เองระหว่างทำงาน และมี native conflict resolution เมื่อ agents สองตัวให้คำตอบที่ขัดแย้งกัน
# MiniMax M2.7 — OpenAI-compatible API
# ใช้ OpenAI SDK ได้เลย แค่เปลี่ยน base_url
from openai import OpenAI
client = OpenAI(
api_key="your-minimax-api-key",
base_url="https://api.minimax.chat/v1"
)
response = client.chat.completions.create(
model="MiniMax-M1", # M2.7 ใช้ model name "MiniMax-M1"
messages=[
{"role": "system", "content": "You are a senior SRE."},
{"role": "user", "content": "Analyze this error log..."}
],
max_tokens=4096,
temperature=0.7
)
print(response.choices[0].message.content)
อะไรใหม่ใน M2.7 — แบบเจาะลึก
ถ้าเคยใช้ M2.5 อยู่แล้ว นี่คือ 5 สิ่งที่เปลี่ยนไปจริงๆ ไม่ใช่แค่ marketing copy:
- 1
Agent Teams (Native Multi-Agent Collaboration)
สร้างทีม AI หลายตัวทำงานร่วมกันได้แบบ native — ไม่ใช่แค่ส่ง prompt chain ไปมาระหว่าง instances แต่เป็น system-level coordination ที่ agents แชร์ working memory, แบ่ง tasks อัตโนมัติ, และ resolve conflicts ได้เองโดยไม่ต้องเขียน orchestration code เพิ่ม ถ้าเทียบกับ Claude MCP หรือ GPT function calling ตรงที่ MiniMax ทำ multi-agent เป็น first-class feature ไม่ใช่ extension
- 2
40+ Complex Skills พร้อม 97% Adherence
โมเดลจัดการ complex skills ได้มากกว่า 40 ตัวพร้อมกัน แต่ละ skill มีขนาด 2,000+ tokens — ด้วย skill adherence rate 97% หมายความว่าเวลาคุณให้ system prompt ที่ซับซ้อนมีหลาย constraints หลาย rules มันจะทำตามได้แม่นยำมาก ตรงนี้เป็นจุดที่หลายโมเดลยังทำไม่ได้ดี โดยเฉพาะเมื่อ skills มีเงื่อนไขที่ขัดแย้งกัน
- 3
Self-Evolution ผ่าน Research Agent Harness
M2.7 เป็นโมเดลแรกของ MiniMax ที่ใช้ตัวเองเป็นส่วนหนึ่งของ development pipeline — ผ่าน autonomous harness refinement กว่า 100 รอบ ระบบจะให้โมเดลวิเคราะห์ว่า harness (ชุดคำสั่งกำกับ) ตรงไหนที่ทำให้ผลลัพธ์ไม่ดี แล้วปรับปรุงเอง วนจนกว่าจะ converge ผลลัพธ์คือการปรับปรุง 30% บน internal evals ซึ่งเป็น approach ที่ต่างจากการ fine-tune แบบเดิมตรงที่ harness improvement ไม่ได้แก้ weights แต่แก้วิธีใช้งานโมเดล
- 4
SRE-Level Incident Resolution
MiniMax อ้างว่า M2.7 แก้ production incidents ได้ภายใน 3 นาที — รวม observability analysis (อ่าน logs, metrics, traces), database expertise (วิเคราะห์ query performance), และ root cause analysis ไว้ในการตอบเดียว สำหรับทีม DevOps/SRE ที่มี on-call rotation นี่คือ use case ที่ถ้าทำได้จริงจะ save ได้ทั้งเวลาและ MTTR
- 5
Professional Document Editing
สร้างและแก้ไข Word, Excel, PowerPoint ได้โดยตรงผ่าน API — ไม่ต้อง convert เป็น text แล้วแปลงกลับ เหมาะกับ enterprise workflow ที่ต้องทำงานกับเอกสารเยอะ เช่น สร้าง report จาก data ที่ดึงมา หรือ update slide deck จาก meeting notes โดย preserve formatting ของเอกสารต้นฉบับ

ที่มา: MiniMax Technical Blog — Research Agent Harness Architecture ที่ใช้ recursive evaluation loop
ตัวเลข Benchmark — ดีจริงหรือแค่เลือกมาโชว์?
MiniMax ปล่อยตัวเลข benchmark มาค่อนข้างครบ 9 benchmarks — ซึ่งเป็นเรื่องปกติที่บริษัท AI จะเลือกแสดง benchmarks ที่ตัวเองทำได้ดี แต่สิ่งที่น่าสนใจคือ MiniMax เลือกแข่งใน benchmarks ที่ หลากหลายจริงๆ ตั้งแต่ coding (SWE-Pro, SWE Multilingual), agent tasks (Toolathon, Terminal Bench), ไปจนถึง machine learning engineering (MLE Bench Lite) ไม่ได้เน้นแค่ MMLU หรือ HumanEval ที่ง่ายต่อการ game
ตัวเลขที่โดดเด่นที่สุดคือ SWE-Pro 56.22% ซึ่ง MiniMax อ้างว่าเทียบเท่า GPT-5.3 Codex — benchmark นี้วัดความสามารถในการแก้ real-world software engineering tasks ที่ pull มาจาก open-source repos จริง ไม่ใช่ synthetic problems ที่แต่งขึ้น ถ้าตัวเลขนี้ถูก verify ได้ มันหมายความว่า M2.7 เป็น open-weight model ตัวแรกที่แตะ frontier ของ code generation ได้
อีกตัวที่ควรจับตาคือ MLE Bench Lite 66.6% — ได้ 9 เหรียญทอง, 5 เงิน, 1 ทองแดง รองแค่ Opus 4.6 (75.7%) กับ GPT-5.4 (71.2%) เท่านั้น เท่ากับ Gemini 3.1 พอดี MLE Bench วัดความสามารถในการทำ machine learning tasks ครบ pipeline ตั้งแต่ data preprocessing, feature engineering, model training ไปจนถึง submission — เป็น benchmark ที่ยากกว่า coding ปกติเพราะต้องมี domain knowledge ด้าน ML ด้วย
| Benchmark | M2.7 | เทียบกับ |
|---|---|---|
| SWE-Pro | 56.22% | เทียบเท่า GPT-5.3 Codex — real-world software engineering |
| VIBE-Pro | 55.6% | ใกล้เคียง Opus 4.6 — visual + interactive benchmarks |
| Terminal Bench 2 | 57.0% | Complex system administration tasks |
| GDPval-AA ELO | 1,495 | สูงสุดใน open-source models — general capability |
| SWE Multilingual | 76.5% | Real-world coding ข้ามหลายภาษา |
| Multi SWE Bench | 52.7% | Repository-level tasks ที่ต้องเข้าใจ codebase ทั้งหมด |
| Toolathon | 46.3% | Global top tier — tool use + multi-step reasoning |
| MM Claw | 62.7% | เทียบเท่า Sonnet 4.6 — complex task completion |
| MLE Bench Lite | 66.6% | อันดับ 3 รองจาก Opus 4.6 (75.7%) กับ GPT-5.4 (71.2%) |

ที่มา: MiniMax Official Announcement — MLE Bench Lite medal breakdown เปรียบเทียบกับ frontier models
ใครควรลองใช้ — และใช้ยังไง?
สมมติคุณเป็นทีม backend ที่กำลังสร้าง Multi-Agent System — เช่น ระบบ customer support ที่ agent ตัวหนึ่งรับเรื่อง อีกตัวดึง order history อีกตัววิเคราะห์ sentiment แล้วตัวสุดท้ายเขียน response Agent Teams ของ M2.7 ให้คุณทำสิ่งนี้โดยไม่ต้องเขียน orchestration layer เอง เพราะ task decomposition เป็น native — แค่ describe roles แล้วปล่อยให้โมเดลจัดการ flow เอง ถ้าเทียบกับ LangGraph ที่คุณต้องเขียน state machine เอง นี่คือ abstraction ที่สูงกว่ามาก
ถ้าคุณอยู่ในทีม DevOps/SRE — claim ที่ว่าแก้ production incidents ได้ภายใน 3 นาทีน่าสนใจมาก ลองนึกภาพ: alert เข้ามาตอนตี 3 คุณส่ง log dump + metrics ให้ M2.7 แล้วมันวิเคราะห์ root cause, suggest fix, และ draft runbook ให้ภายในเวลาที่คุณยังไม่ทันชงกาแฟ ถ้าผ่านการ verify ในสภาพแวดล้อมจริงได้ มันจะลด MTTR ได้อย่างมีนัยสำคัญ แต่ต้องเน้นว่า "ถ้า" เพราะ production environment ไม่เหมือน benchmark ที่ clean
Enterprise teams ที่ทำงานกับเอกสารเยอะ — หลายองค์กรในไทยยังใช้ Word/Excel เป็นหลักในการ report ถ้า M2.7 edit เอกสารเหล่านี้ได้โดยตรงโดย preserve formatting มันจะลด friction ในการเอา AI มาใช้กับ workflow จริงได้มาก ลองนึกภาพ: ส่ง meeting notes เข้าไป แล้วได้ slide deck ออกมาพร้อม formatting ถูกต้อง ไม่ต้อง copy-paste จาก ChatGPT ไปใส่ PowerPoint เอง
คนที่ใช้ M2.5 อยู่แล้ว — ถ้า benchmark numbers เป็นจริง M2.7 เป็น upgrade ที่คุ้มค่าชัดเจน โดยเฉพาะด้าน coding และ agent capabilities เนื่องจาก API เป็น OpenAI-compatible format การย้ายจาก M2.5 มา M2.7 ทำได้แค่เปลี่ยน model name ใน request โดยไม่ต้องแก้ code ส่วนอื่น และถ้าคุณใช้ GPT อยู่ การ migrate มาทดสอบก็แค่เปลี่ยน base_url
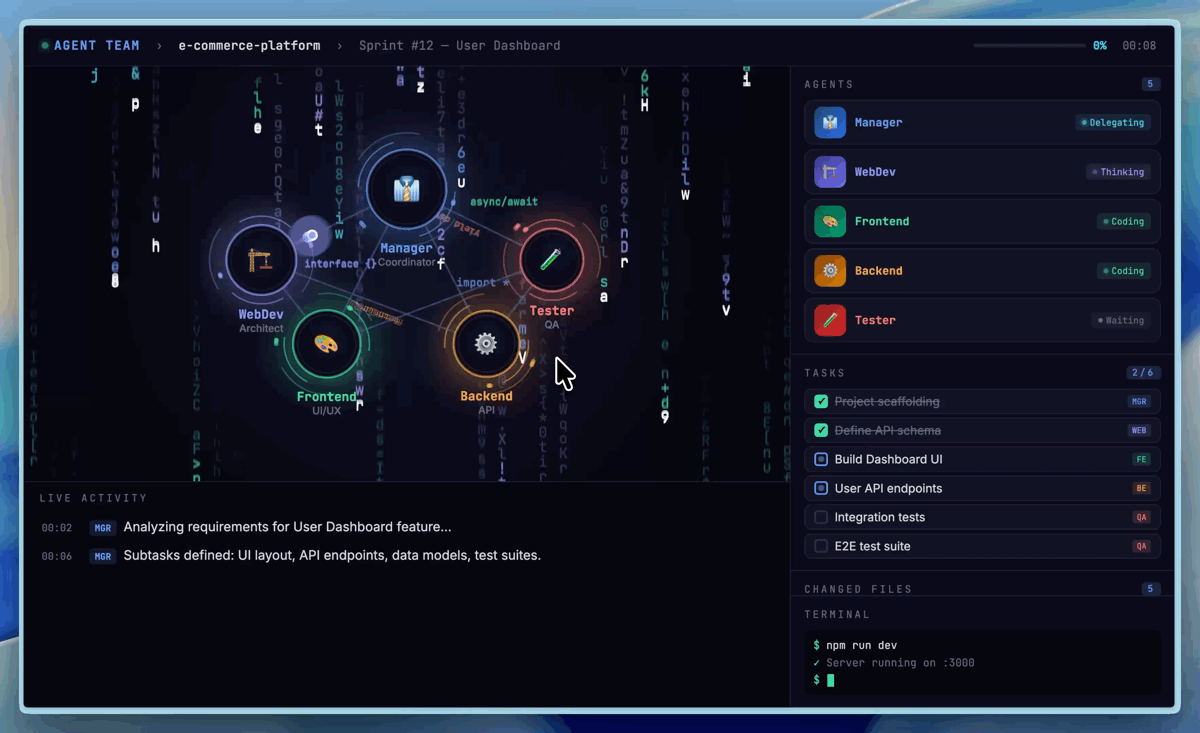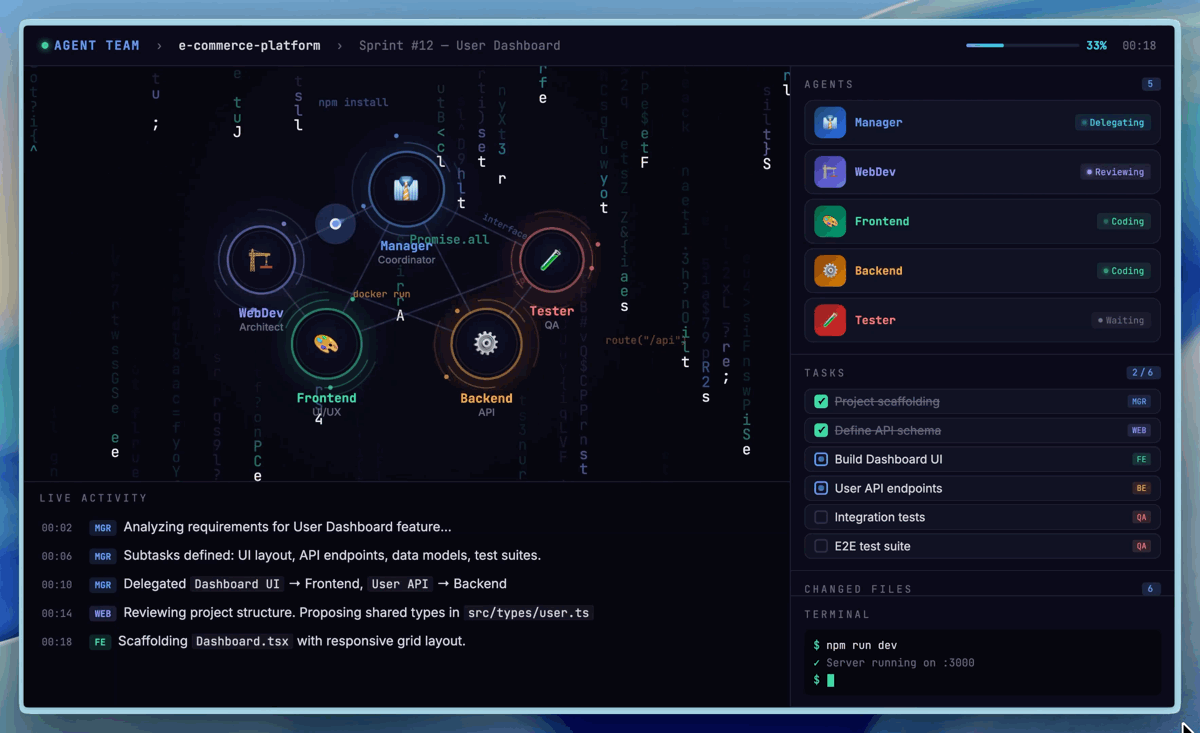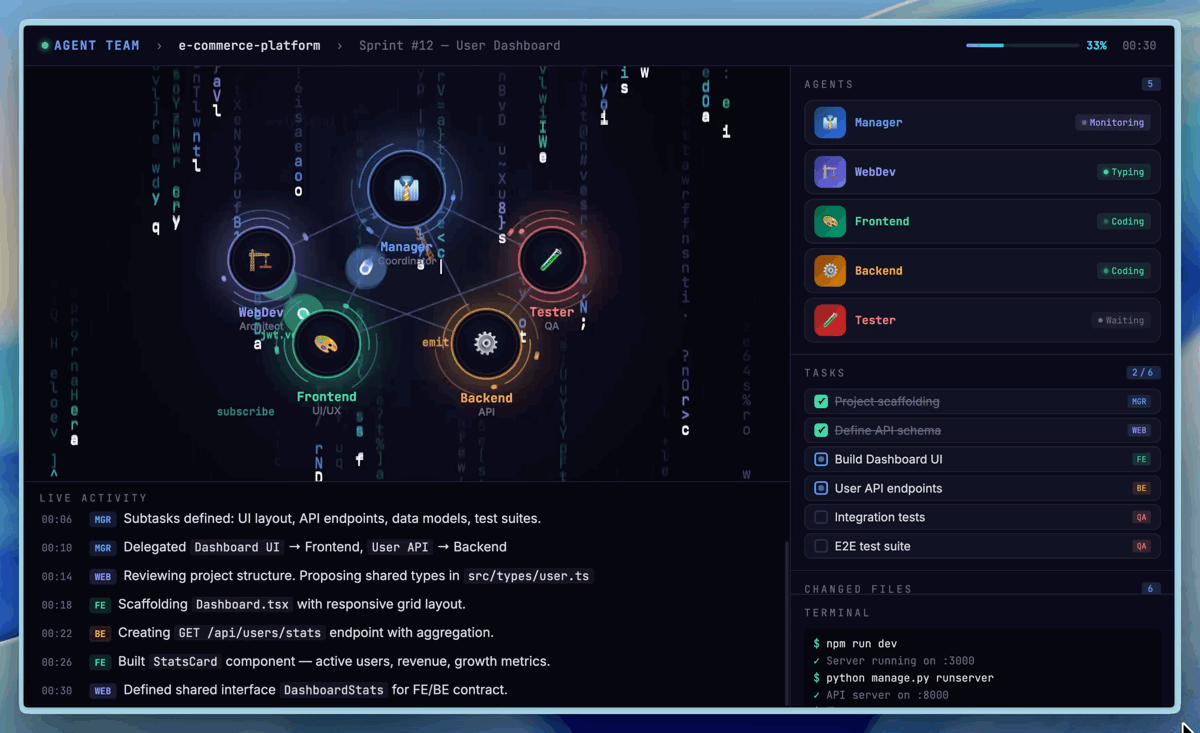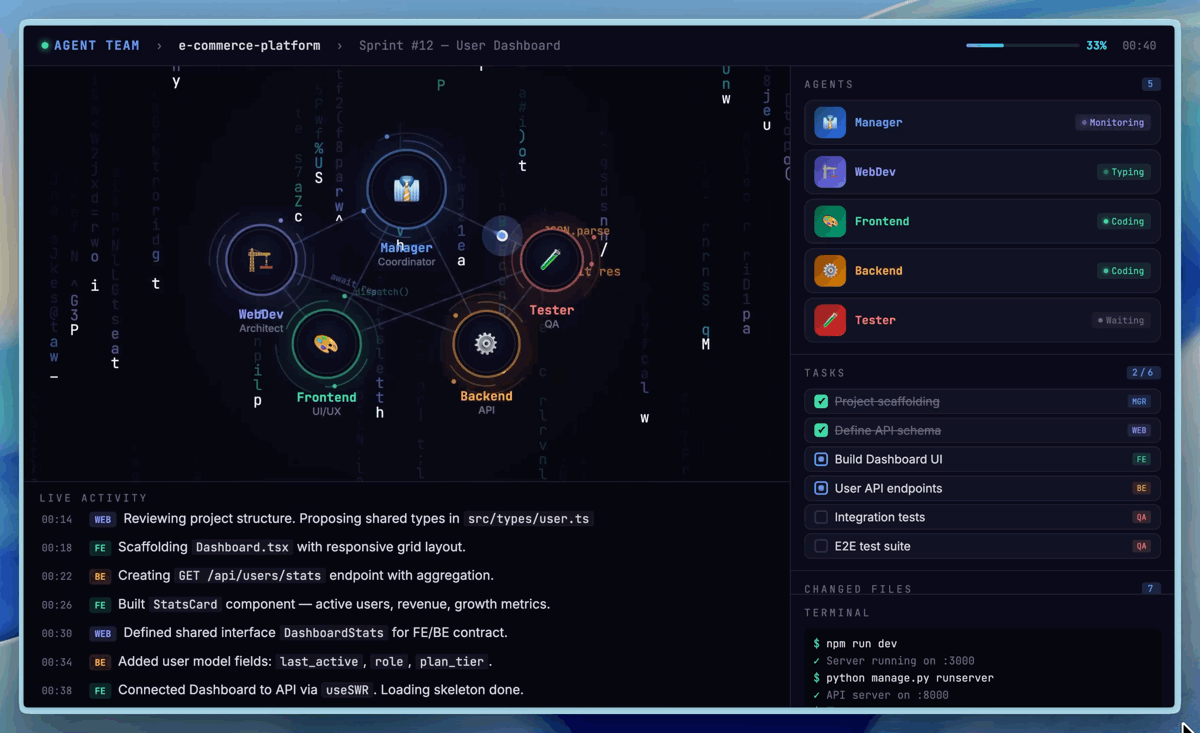
ที่มา: MiniMax Agent Platform — Demo การทำงานของ Agent Teams แบบ multi-agent collaboration
ต้องบอกตรงๆ ว่า... มีหลายอย่างที่ต้องตั้งคำถาม
ต้องบอกตรงๆ ว่าตัวเลข benchmark ทั้งหมดที่กล่าวมา มาจาก MiniMax เอง ยังไม่มี third-party verification จาก independent labs อย่าง Holistic AI, LMSYS, หรือแม้แต่ community leaderboard อย่าง Chatbot Arena ที่ยืนยันตัวเลขเหล่านี้ ในโลกของ AI ที่ทุกบริษัทแข่งกันปล่อย benchmark สวยๆ สิ่งที่ขาดไปคือ reproducibility — ถ้าเราไม่สามารถ reproduce ตัวเลขเหล่านี้ได้เอง มันก็เป็นแค่ marketing claim
เรื่อง "self-evolution" ก็ต้องเข้าใจให้ตรง — ฟังดูเหมือนโมเดลพัฒนาตัวเองแบบ AGI ในหนัง แต่จริงๆ แล้วมันคือ automated prompt/harness optimization ที่ใช้โมเดลเป็นส่วนหนึ่งของ feedback loop การที่โมเดลช่วยปรับปรุง harness ของตัวเองเป็นเรื่องน่าสนใจทาง engineering แต่มันไม่ได้ "พัฒนาตัวเอง" ในความหมายที่คนทั่วไปเข้าใจ weights ของโมเดลไม่ได้เปลี่ยน — เปลี่ยนแค่วิธีใช้งาน
แล้วก็ต้องพูดถึง benchmark culture ที่เป็นปัญหาใหญ่ของวงการ AI ตอนนี้ — ทุกบริษัทเลือก benchmarks ที่ตัวเองชนะมาโชว์ MiniMax ไม่ได้ทำผิดอะไร แต่ก็ไม่ได้บอกว่า M2.7 แพ้ที่ไหนบ้าง ไม่มี benchmarks ด้าน reasoning แบบ GPQA, math competition แบบ AIME, หรือ long-context tasks ที่อาจเป็นจุดอ่อน ถ้าโมเดลดีจริงทุกด้าน ทำไมไม่โชว์ทุก benchmark?
Agent Teams เป็นของใหม่มาก — เพิ่ง launch วันที่ 18 มีนาคม 2026 ยังไม่มี production case studies ที่ verify ได้ ไม่มี developer community ที่ใหญ่พอจะรู้ gotchas และ edge cases เวลาใช้งาน technology ใหม่ในสภาพแวดล้อมจริง ปัญหาที่เจอมักจะต่างจากที่เจอใน benchmark มาก
สุดท้าย — ราคายังไม่ชัดเจน MiniMax มี Coding Plans แยกแต่ pricing structure ของ M2.7 API ยังไม่ได้ระบุชัดเจนว่า cost per token เท่าไหร่ เทียบกับ GPT-5.3 หรือ Claude ยังไง ถ้าไม่รู้ราคา คุณก็คำนวณ ROI ไม่ได้ และสำหรับ production use case ที่ volume สูง ราคาต่อ token สำคัญกว่า benchmark score เสมอ
Agent Teams vs Claude MCP vs GPT Function Calling: ทั้ง 3 แนวทางแก้ปัญหาเดียวกัน — ให้ AI ใช้ tools ได้ แต่วิธีคิดต่างกัน
Claude MCP เน้นเปิด protocol มาตรฐานให้ tools ต่างๆ เชื่อมต่อได้ (เหมือน USB-C ของ AI) GPT Function Calling เน้นให้โมเดลเรียก functions ที่ developer กำหนดไว้ล่วงหน้า ส่วน Agent Teams เน้นที่ multi-agent coordination — ให้ agents หลายตัวแบ่งงานและทำงานร่วมกันเอง ในทางปฏิบัติ Agent Teams เหมาะกับ tasks ที่ต้องใช้ "ทีม" จริงๆ เช่น code review + testing + deployment pipeline ขณะที่ MCP และ Function Calling เหมาะกับ single-agent + tools มากกว่า
จุดแข็ง
- Benchmark ระดับ frontier ทั้ง coding, agent tasks, และ ML engineering — ไม่ใช่แค่ MMLU สูง
- Native Agent Teams ที่ built-in มากับ architecture — ไม่ต้องพึ่ง external framework
- OpenAI-compatible API — migrate จาก GPT มาทดสอบได้ภายในนาที
- 97% skill adherence สำหรับ complex multi-skill instructions — เหมาะกับ production prompts ที่ซับซ้อน
- SRE-level debugging — ถ้า verify ได้จะเป็น game changer สำหรับ on-call workflows
- Document editing (Word/Excel/PPT) แบบ native — ลด friction สำหรับ enterprise adoption
ข้อควรระวัง
- ตัวเลข benchmark ทั้งหมดเป็น self-reported — ยังไม่มี third-party verification
- ราคา API ยังไม่ชัดเจน — คำนวณ ROI ไม่ได้จนกว่าจะรู้ cost per token
- Context window ไม่เปิดเผย — ไม่รู้ว่ารองรับเอกสารยาวได้แค่ไหน
- Agent Teams ใหม่มาก — ยังไม่มี production battle scars หรือ community gotchas
- ไม่มี image/audio generation — เน้น text, code, และ document เป็นหลัก
- ไม่แสดง benchmarks ด้าน reasoning (GPQA) หรือ math (AIME) — อาจเป็นจุดอ่อน
Coding Plan: MiniMax มี Coding Plan แยกสำหรับ developer — Starter (¥29/เดือน), Plus (¥49/เดือน), Max (¥119/เดือน) แต่ราคา API token สำหรับ M2.7 โดยเฉพาะยังไม่เปิดเผย — ต้องติดตามที่ platform.minimax.io
ลองเปรียบเทียบ MiniMax M2.7 กับ GPT-5.4, Claude Opus 4.6, Gemini 3.1 ด้วยตัวเอง
เริ่มใช้งานแหล่งข้อมูล
- MiniMax M2.7 Official Announcement — รายละเอียดฉบับเต็ม
- MiniMax Agent Platform — ทดลองใช้ Agent Teams
- MiniMax API Platform — Coding Plans และ API documentation
- SWE-Bench — Software Engineering Benchmark ที่ใช้อ้างอิง
- MLE Bench — Machine Learning Engineering Benchmark



